Chapitre Ecrire une grammaire avec ANTLR
Ecrire sa première grammaire avec ANTLR
Cette leçon fournit les bases pour comprendre ce qu'est la compilation
Ecrire sa première grammaire avec ANTLR
Le workflow pour l'écriture d'une grammaire
- Créer un fichier grammaire.g4
Le fichier contient les règles du langage que vous analysez
Pour compiler une grammaire en ligne de commande, vous appelez :
antlr4 <options> <grammaire.g4>
Nous avons vu également qu'il existait un outil pour tester les grammaires (TestRig) utilisable sous l'alias grun
grun <grammar-name> <rule-to-test> <input-filename(s)>
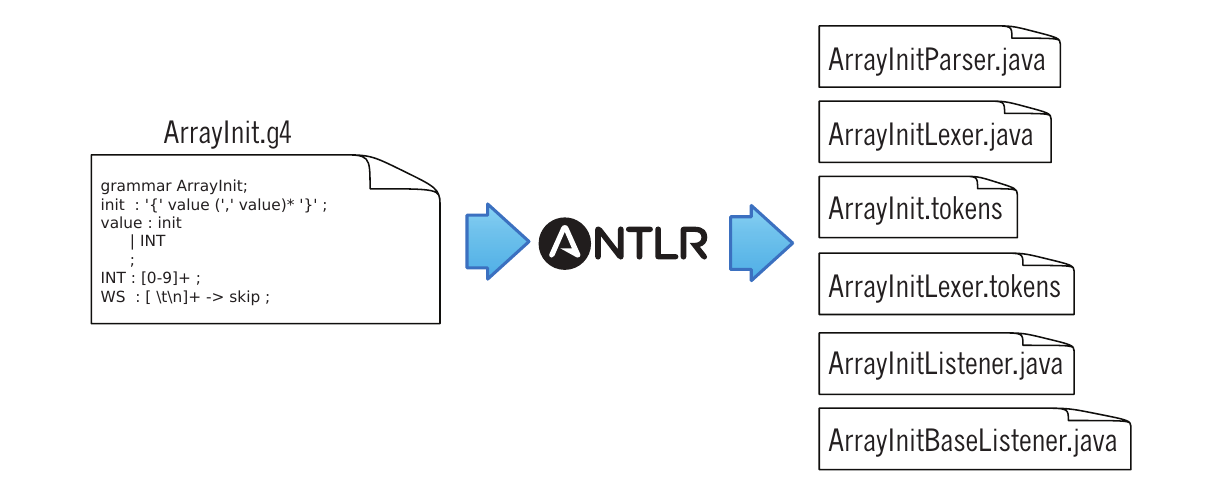
Fichiers générés
ANTLR génère trois types de fichiers :
- Le Lexer et le Parser dans le langage cible (Java, python...)
- les fichiers
*.tokensqui contiennent les noms des tokens et leurs valeurs numériques - les fichiers
*.interpqui contiennent des informations pour le debogage dans les IDE
La structure classique d'un fichier ANTLR est :
/*
* Règles de parsing
*/
operation : NOMBRE '+' NOMBRE ;
/*
* Règles de lexing
*/
NUMBER : [0-9]+ ;
WHITESPACE : ' ' -> skip ;
Convention de nommage
- Les règles de lexing sont en MAJUSCULES
- Les règles syntaxiques en minuscules
- même si en pratique la règle ne s'applique qu'au premier caractère.
Exemple réel :
IS_FIXED : [iI] -> popMode,pushMode(FIXED_InputSpec) ;
PS_FIXED : [pP] -> popMode,pushMode(FIXED_ProcedureSpec) ;
HS_FIXED : [hH] -> popMode,pushMode(HeaderSpecMode) ;
BLANK_LINE : [ ] [ ]* NEWLINE -> popMode,skip;
BLANK_SPEC_LINE1 : . NEWLINE -> popMode,skip;
BLANK_SPEC_LINE : .[ ] [ ]* NEWLINE -> popMode,skip;
COMMENTS : [ ] [ ]*? '//' -> popMode,pushMode(FIXED_CommentMode), channel(HIDDEN) ;
DIRECTIVE : . [ ]*? '/' -> popMode,pushMode(DirectiveMode_Start) ;
Les méthodes de conceptions d'une grammaire
Les approches
- L'approche Bottom-up (par le lexeur)
- L'approche Top-down (par l'analyseur syntaxique)'
L'approche Bottom-up
L'approche bottom-up consiste à partir depuis le Lexeur, couvrir l'ensemble des tokens puis remonter au niveau du parseur lui-même
Avantages / inconvénients
- Il est possible de vérifier que le Lexer n'est ainsi pas buggé individuellement
- La grammaire est écrite petit morceau par petit morceau via des tests unitaires.
L'approche Up-bottom
Cette approche consiste généralement à partir d'une spécification d'un langage de programmation (certaines grammaires sont disponibles) et de recoder cette grammaire complètement en ANTLR.
Avantages / inconvénients
- C'est l'approche qui semble naturelle quand on possède déjà une grammaire normalisée comme spécification
- Les tests arrivent trop tardivement dans la construction du parseur, si la grammaire a une erreur, le débogage va être complexe.
Les règles de lexing
- L'expression d'une règle de lexing ressemble à une expression régulière
- Il est possible d'utiliser la notion de
fragmentpour décomposer l'expression du token
La notion de fragment
Un fragment permet la réutilisation d'une partie d'expression :
fragment DIGIT : [0-9] ;
NUMBER : DIGIT+ ([.,] DIGIT+)? ;
La notion de mode lexical
Parfois un langage de programmation contient plusieurs modes de programmation au sein de sa grammaire.
Ainsi en Cobol, on peut écrire du SQL.
Cela rend l'écriture de telles grammaires très complexe.
Pour définir un mode lexical vous utilisez la syntaxe suivante :
mode Selector;
.../...
mode DirectiveTitle;
.../...
mode DirectiveMode_Start;
.../...
mode CopyMode;
.../...
Pour quitter le mode dans lequel nous sommes entrés, il faut écrire une action avec la syntaxe suivante :
COPY_NA : -> popMode;
Les règles syntaxiques
/*
* Règles de parsing
*/
grammar Expr;
prog: (expr NEWLINE)* ;
expr: expr ('*'|'/') expr
| expr ('+'|'-') expr
| INT
| '(' expr ')'
;
NEWLINE : [\r\n]+ ;
INT : [0-9]+ ;
Le nom du parseur est défini avec grammar Expr et le nom du fichier doit être équivalent.
Il est possible de découper la grammaire entre le lexer et le parser en deux :
Parser
parser grammar RpgParser;
options { tokenVocab = RpgLexer; }
Lexer
lexer grammar RpgLexer;
